It’s always hard to believe another year is over. But it’s also a great time to think about reading goals for the year to come. I’m not talking about secondary literature (although I do plan to post a “What I Read in 2019” list soon), but about primary literature. When people ask me why they should care about the Septuagint, one of the things I mention is its language. If you are a student of postclassical (Koine) Greek, then the Septuagint is a natural next step (so too are the Patristic writers). That was a major reason why Greg Lanier and I set out to produce Septuaginta: A Reader’s Edition (Hendrickson 2018).
So with that in mind, I thought I’d present two good ways to begin (or continue) reading the Septuagint in 2020.
1. Going Deep in One or Two Books
The first possibility is to choose a book (or two) and simply dive in at the beginning with the intention of reading all the way through. This can be an intimidating prospect for a few reasons. You may be asking, “I have no clue where to begin — which books are managable based on my knowledge of NT Greek?” That’s a question we anticipated when we created the Reader’s Edition, and one we didn’t have a good answer to. So we gathered data and found answers.
Below is a ranking index of each book of the Septuagint (in a few cases, groups of books) that moves from easier to harder. The criteria we used to help create this index were objective. Things like range and frequency thresholds of vocabulary used in the book, the degree of overlap between that range and NT vocabulary, average length of sentences, number or participles per sentence, and even the amount of time that it took us to produce the draft for each chapter of the book in the Reader’s Edition (yes, we timed ourselves).
So using the index, you can select a book based on your general confidence level and just go for it. Here’s the index:

And for some more detail on the Twelve Prophets corpus, here’s an index with each individual book ranked:
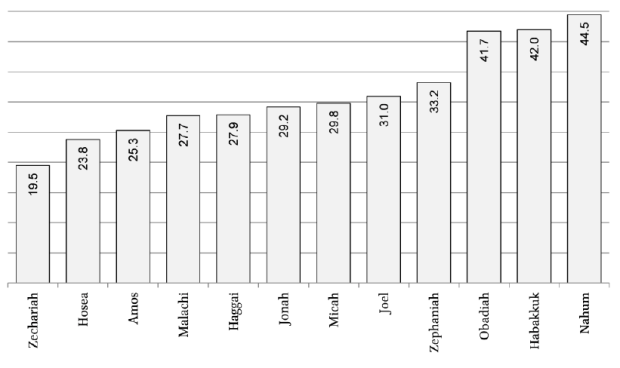
 Now, you may be saying “A difficulty ranking index is great and all, but I probably still don’t know a bunch of the vocabulary in any given book. Won’t that create a huge barrier?”
Now, you may be saying “A difficulty ranking index is great and all, but I probably still don’t know a bunch of the vocabulary in any given book. Won’t that create a huge barrier?”
Answer: Yes. But there’s a solution! The solution is our Book-by-Book Guide to Septuagint Vocabulary (Hendrickson 2019). We designed the book to work hand-in-hand with the Reader’s Edition. We created a number of strategic lists for the whole Septuagint corpus, and for each individual book, so that the more vocabulary you get under your belt, the easier your reading experience will be. Put differently, the more vocabulary lists you memorize for, say, the book of Genesis, the less often you will have to look down to consult the lower apparatus with parsing and contextual glosses as you read. You will be surprised how much a little good-old-fashioned memory work can do!
2. Reading Across the Whole Corpus with Increasing Difficulty
A second strategy for getting into the habit of reading the Septuagint is to work across the entire corpus in small chunks. Last year I posted a graded reading plan that is designed for exactly this purpose, and I repost the plan below.
Now, you may be saying, “Come on, Ross. Why didn’t you re-do the plan so we have fresh readings to work with?” Well, to be honest, I didn’t really feel like it. But also, the very fact that you have the graded difficulty index (above) means that you don’t really need me to plan out reading chunks for you. In fact, you don’t even need the guide that I created (although it does have a few convenient features). You can simply use the index to work your way up the curve of difficulty in small selections of your own choosing.
But if you didn’t use the plan last year — or fell off the bandwagon — or hit a wall at some point when you felt you weren’t able to handle the Greek — here is the plan in full. Have another stab at it!
Please share this reading plan freely!
Whatever way you choose to do it, I hope that these resources help you get into the Greek language and text of the Septuagint in new ways this coming year!

Reblogged this on Zwinglius Redivivus and commented:
Just do it.
Thanks for this, Will – I hope to leverage it a bit this year!
Thanks so much for this, Will. I had just subscribed to your website and this was the first post I received. It was perfect for rounding out my language study goals for the New Year.
Many people in my greek class are wondering how many unique words are in the LXX but not in the GNT. Would you happen to have the statistic handy?
Great question. The answer is probably “more than you think.” Based on our parameters and base texts (Rahlfs-Hanhart and NA28), there are 13,827 unique lexemes in the Septuagint and 5,386 unique lexemes in the NT. When you eliminate the words shared between the two corpora, there are still 9,876 unique lexemes in the Septuagint. However, of those, 4,308 are proper nouns (most of which are transliterations and fairly easy to grasp), leaving 5,858 unique lexemes in the Septuagint excluding proper nouns. Note how that figure is actually slightly higher than the total number of unique lexemes in the NT! Hopefully this helps (and also helps explain why we felt the vocabulary guide was a necessary evil!).
Thank you so much for the reply, both from me, and from my classmates. If I might ask another question, how many of the 4308 proper nouns are also hapax ? To put it another way, my Memrise deck shows 5653 “words.” I wonder how many of those are Hapax?
Great question. Again, the answer is “a lot”. Again, there are 9,876 unique lexemes in the Septuagint when you eliminate shared words with the NT corpus.Of those, 4,308 are proper nouns and 5,858 are not. Of those two categories, there are 2,551 hapax proper nouns (59.2%) and 2,798 hapaxes out of non-proper noun lexemes (47.7%).
Wow! almost 60% of the Hapax are proper nouns! It’s all very interesting. I’m working on this vocabulary this year, and this is making it more likely that I will complete my goals. BTW, I’m reading through the LXX this year, in your wonderful volumes, so your blog post and comments are very useful to me. Thank You so much!
Very glad to hear you’re enjoying the Reader. Assuming you are also using the vocabulary book, bear in mind:
(1) We did not include any proper nouns
(2) We only rarely include words with very low frequency
The reason for (2) is due to our graduated “competency” level for each book. So rather than simply providing vocabulary down to, say, 10x for each book, instead we provide lists that account for the diversity of lexemes in a given book and provide as many lists as necessary to get the reader to 90% knowledge of the lexical stock of a book. So it’s a bit of a customized approach that we thought handled the wide range of vocabulary a little more strategically.
Yes, thanks. I have both books and understood this. I also think it is the right strategy. I’m not 100% sure yet of my strategy for the reading. I’ve been using this for “extensive reading,” to make my comprehension more fluent. At the same time I plan to work the vocabulary in various ways, one of which is to use the Memrise compete LXX deck, featuring 13,428 words. [ref: https://www.memrise.com/course/1508311/lxx-greek-old-testament/%5D I’m also hoping to record your lists from your vocab book, and listen to them when I’m running, hopefully in coordination with the reading, so that I’m listening/learning glosses prior and during reading. I haven’t fully worked out the schedule/logistics of this yet, but this is the rough plan. I’m wavering a bit on the re-reading part. Right now, I’m reading an hour a night, 5 chapters a night. Some of the research I’ve done on acquisition holds that “training the eye” to read at normal levels is an important skill, which can only be acquired by reading comprehensible input at the normal reading speeds, while taking it in. I can’t possibly do that on one reading. But if I go down this path, I will most likely miss the goal of completing the LXX by years end. Sorry, if this was TMI. 🙂
Great plan!
I’m right on schedule for 2020 – reading Habakkuk (Ambacoum) today. A more timely scriptural reading I cannot imagine.
So what are you doing for us in 2021?
Not sure yet! Perhaps I’ll work up another one.